マニュアルML
データ内の目的変数列と説明変数列を指定して機械学習モデルを構築できます。
マニュアル ML はオート ML とは異なり、ユーザーがデータ前処理と学習アルゴリズムの設定を自由に行える機能です。
各項目は複数設定可能であり、その場合、最も精度の高い組み合わせを自動探索します。
モデルの構築だけでなく、回帰分析、決定木分析、要因分析にも利用できます。
また、オート ML 同様、構築したモデルの重視点などの解釈に関する情報も提供します。
入出力定義
| 定義 | 内容 | 補足 |
|---|---|---|
| 入力 | データ | |
| 左出力 | 機械学習モデル | |
| 中出力 | データ | モデルの精度指標を出力 |
| 右出力 | データ | 説明変数の重要度などを出力 |
| ボニートくん | 精度検証結果 | |
| ボニートくん | 機械が重視したデータ | |
| ボニートくん | 学習プロセス | |
| ボニートくん | 精度改善の余地 | |
| ボニートくん | モデル詳細情報 |
サンプル
処理内容補足
実施する前処理
精度が最大化するように自動的に処理を選択します。
- 欠損値処理
- 数値列の変換 (Box-Cox 変換など)
- 文字列の変換 (ワンホットエンコーディングなど)
- 数値の外れ値処理
- 特徴量選択
前処理設定ダイアログ
前処理設定ボタンをクリックすることで開く各前処理の設定を行うダイアログです。
ダイアログ内で設定した処理の組み合わせを自動探索し、最も精度の高いモデルを構築します。
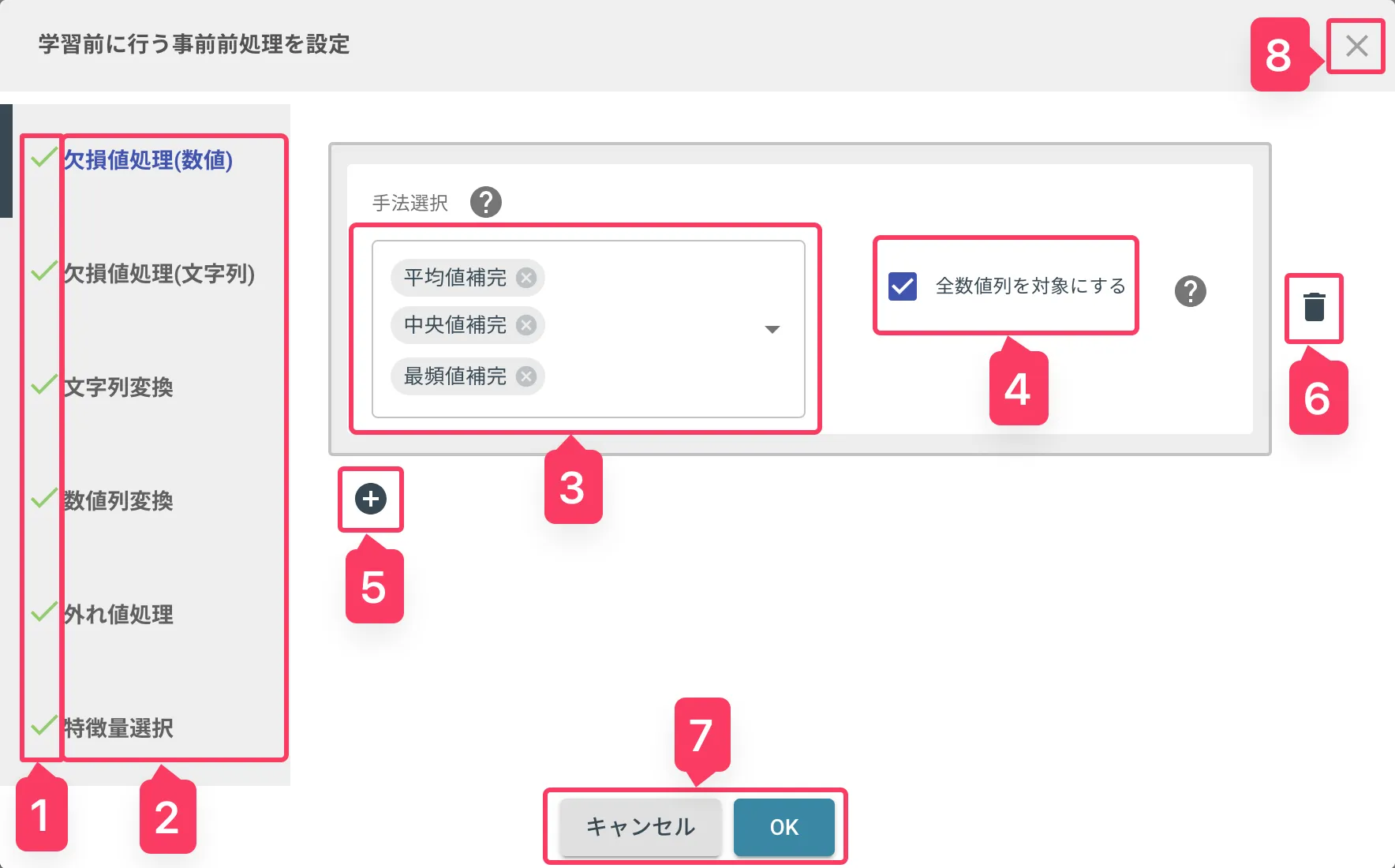
1. 設定ステータス
各前処理の設定状況を示すステータスを表示します。
- 緑のチェックマーク: 設定済みかつ正常な状態
- 赤のバツマーク: 設定済みだが、何らかの問題がある状態
- マークなし: 未設定状態
2. 前処理一覧
前処理候補名の一覧です。
クリックしてフォーカスがあたった状態の処理名は青字になり、3~6 にて設定を行うことができます。
3. 手法候補選択
対象の前処理について、詳細の手法を選択できます。
選択した手法の中から最も精度の高いものを列ごとに自動探索します。
4. 前処理対象列選択
前処理する対象の列を選択できます。
初期状態は全ての列が選択されており、チェックを外すことで任意の列を選択できます。
5. ルール追加ボタン
前処理適用ルールを追加するボタンです。
これを追加することで、例えば下記のような組み合わせが可能になります。
- 列 A,B には平均値補完 or 中央値補完から探索
- 列 C には中央値補完 or 最頻値補完から探索
6. ルール削除ボタン
5 で追加したルールを削除できます。
また、ルールを全て削除することで、対象の前処理自体を適用しないことも可能です。
7. 決定コマンド
- OK: 設定した前処理を適用し、ダイアログを閉じる
- キャンセル: 設定変更を破棄し、ダイアログを閉じる
8. 閉じるボタン
キャンセルと同様の動作をします。
前処理設定状態
ダイアログで設定した前処理は、下記のように処理設定フィールドにプレビューとして表示されます。

学習に用いるアルゴリズム
精度が最大化するように自動的に処理を選択します。
- ランダムフォレスト
- XGBoost
- LightGBM
- CatBoost
- SVM
- 回帰分析
- 一般線形モデル
- ロジスティック回帰
- 線形混合モデル
- 決定木
学習アルゴリズム設定ダイアログ
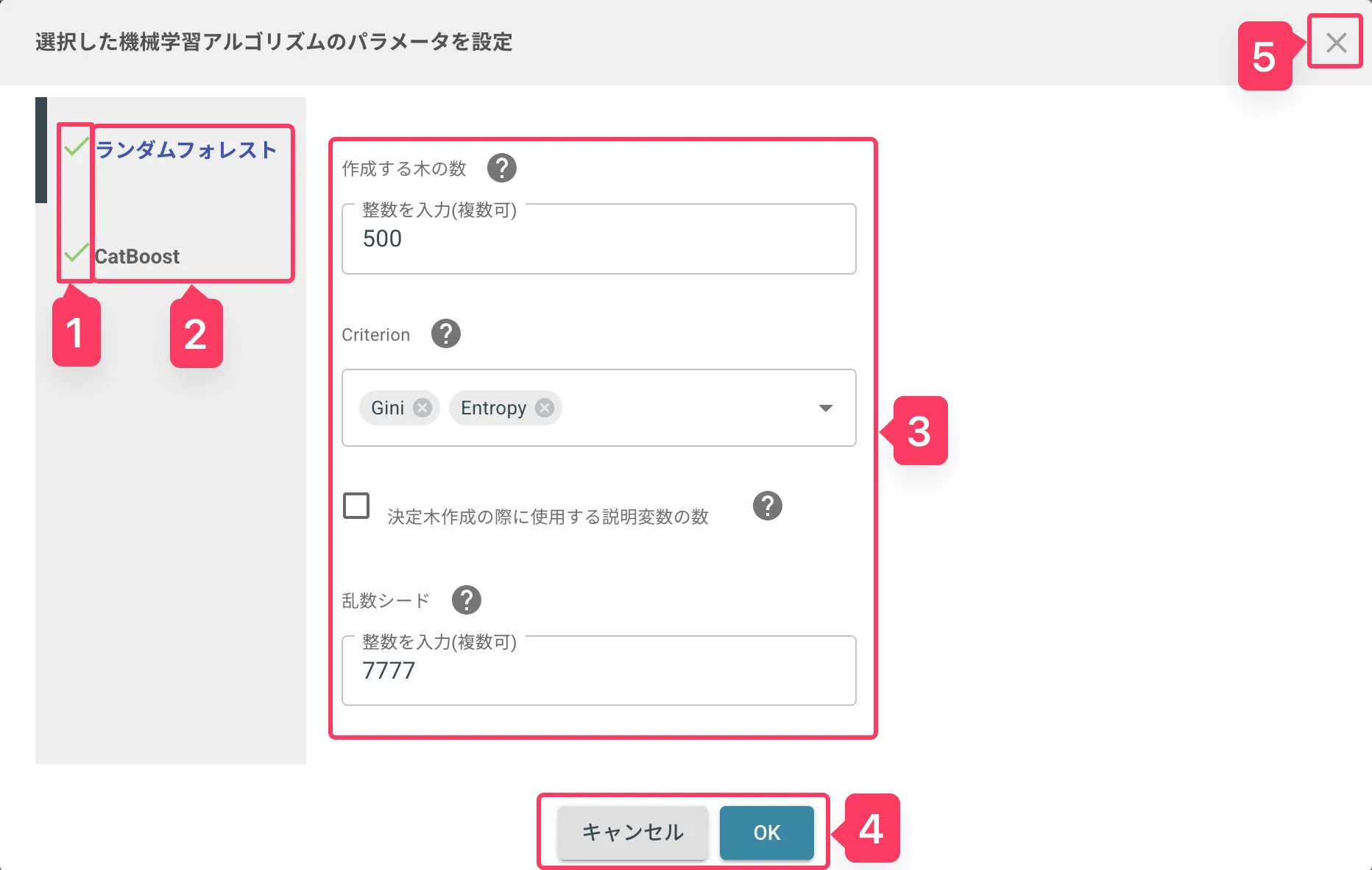
1. 設定ステータス
各学習アルゴリズムの設定状況を示すステータスを表示します。
- 緑のチェックマーク: 設定済みかつ正常な状態
- 赤のバツマーク: 設定済みだが、何らかの問題がある状態
2. 学習アルゴリズム一覧
学習アルゴリズム候補名の一覧です。
クリックしてフォーカスがあたった状態のアルゴリズム名は青字になり、3 にて設定を行うことができます。
3. パラメータ設定
対象の学習アルゴリズムについて、詳細のパラメータを設定できます。
4. 決定コマンド
- OK: 設定した学習アルゴリズムを適用し、ダイアログを閉じる
- キャンセル: 設定変更を破棄し、ダイアログを閉じる
5. 閉じるボタン
キャンセルと同様の動作をします。
学習アルゴリズム設定状態
ダイアログで初期状態から変更したパラメータは、下記のように処理設定フィールドにプレビューとして表示されます。

探索ロジック
ベイズ最適化に基づき、最適な精度を持つ組み合わせを探索します。 これにより高い精度を短時間で実現できます。探索回数の上限は処理モードで制御できます。
処理設定補足
処理モード
速度重視
実行時間を優先し、精度が劣る場合があります。
| パラメータ | 値 |
|---|---|
| 学習に使うデータの行数比率 | 30% |
| 特徴量選択の上限探索回数 | 3 |
| 学習アルゴリズムの上限探索回数 | 3 |
| アンサンブルモデルを構築 | する |
精度重視
時間がかかっても精度を追求するモード。探索回数が増えるため、過学習リスクが上がることがあります。
| パラメータ | 値 |
|---|---|
| 学習に使うデータの行数比率 | 70% |
| 特徴量選択の上限探索回数 | 10 |
| 学習アルゴリズムの上限探索回数 | 10 |
| アンサンブルモデルを構築 | しない |
カスタム
| パラメータ | 値 |
|---|---|
| 学習に使うデータの行数比率 | 任意設定可能 |
| 特徴量選択の上限探索回数 | 任意設定可能 |
| 学習アルゴリズムの上限探索回数 | 任意設定可能 |
| アンサンブルモデルを構築 | しない |
最大化する指標(オプション)
どの精度を最大化するモデルを構築するかを選択可能です。
カテゴリ分類の場合
- 正解率[Accuracy]
- F 値[F1]
- 再現率[Recall]
- 適合率[Precision]
数値予測の場合
- 平均絶対相対誤差[MAPE]
- 平均絶対誤差[MAE]
- 二乗平均平方根誤差[RMSE]
出力内容補足
モデルの精度指標(中出力)
モデルの精度を確認するための以下の項目を出力します。
| 項目 | 説明 |
|---|---|
| 採用モデル | 学習に採用されたアルゴリズムを表示 |
| 精度指標値 | 選択した指標の値を表示 |
| 精度評価 | 精度指標値に基づく評価を表示 |
| 過学習リスク(10 段階) | モデルの過学習リスクを 10 段階で表示 |
モデル補足情報(右出力)
採用モデルによって異なります。
回帰モデルの場合
- 線形回帰
- 一般化線形モデル
- ロジスティック回帰
の場合、説明変数ごとの相関係数など回帰モデルの解釈情報を出力します。
回帰モデル以外の場合
モデル構築時の説明変数ごとの重要度を出力します。重要度が高いほどモデルが重視した変数です。