精度改善の余地
機械が重視したデータと見た目は似ていますが、中身は全く違います。
予測と実測を比較し、どの列が原因で予測が外れてしまっているのかを確認できます。
原因比較
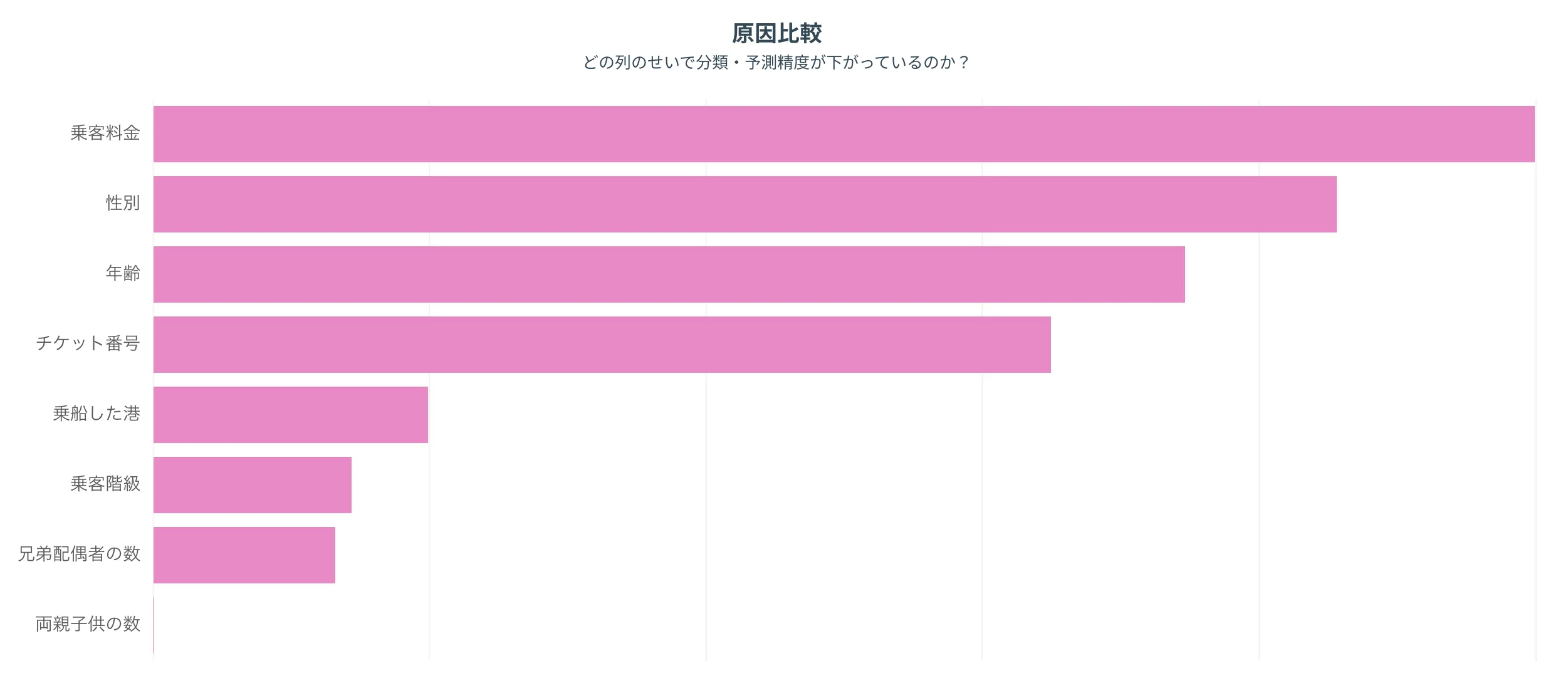
どの列のせいで精度が下がっているのか、を把握できます。
上にある列ほど重要、つまり精度悪化の要因になっている列であることを意味します。
列ごとに詳細を観察
下部のフィルタボックスで列名を指定することで、その列内のどの要素が足を引っ張っているかがわかります。
文字列の場合はカテゴリごとに、数値列の場合は数値範囲ごとに、精度プラス or マイナスに影響したかを表現します。
文字列型の例
下記の性別列を題材にします。
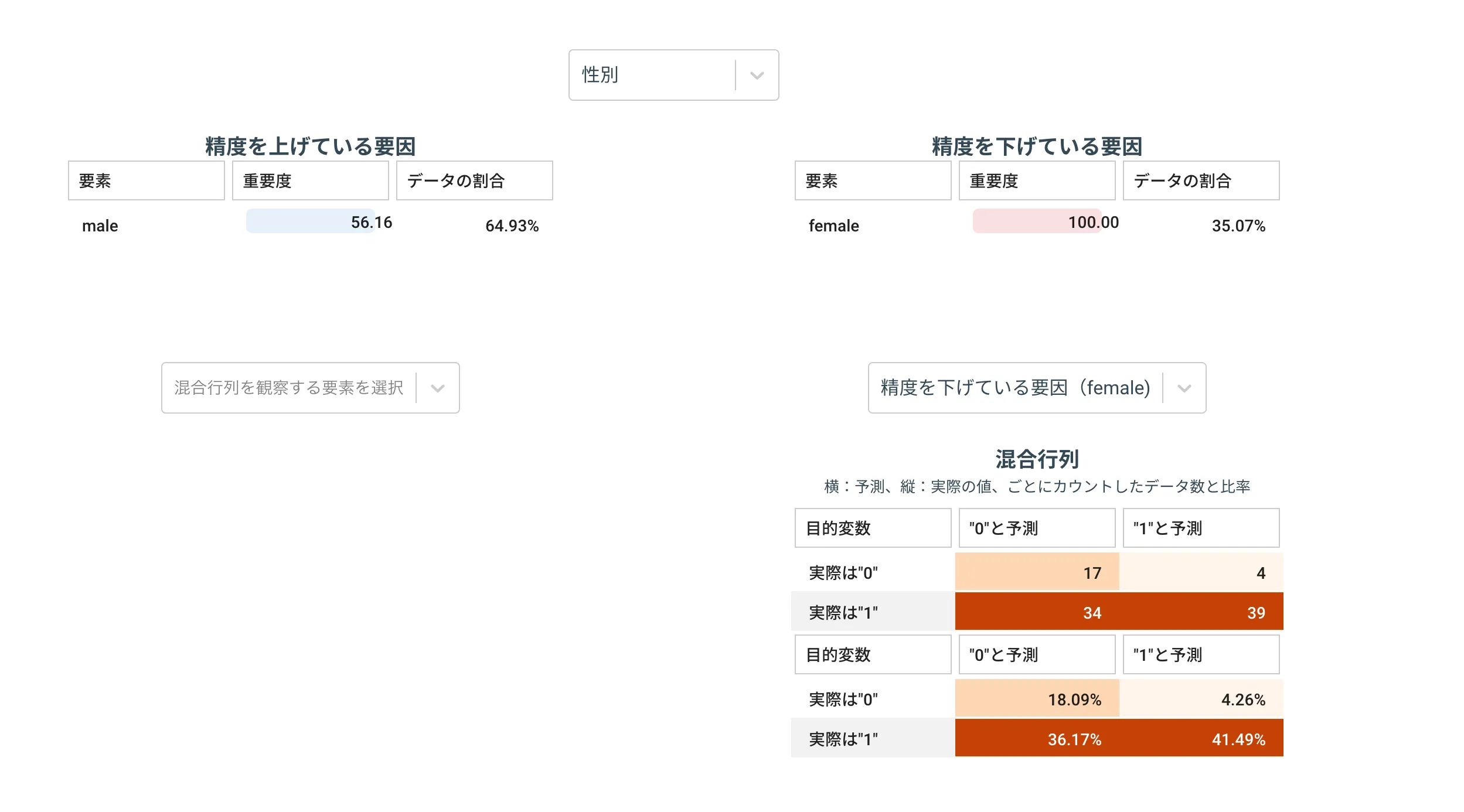
列の値がfemaleの場合、予測が外れている(精度を下げている要因)と解釈できます。
また、混合行列で詳細を確認すると、0と予測したが実際は1だった、つまり予測が外れているデータ数が 36%と非常に多いことがわかります。
つまり、列の値がfemaleの場合、1と予測するためのデータが不足していると言え、説明変数の構成を検討する材料となります。
数値型の例
下記の年齢列を題材にします。
列の範囲16 歳〜21 歳が最も予測が外れている(精度を下げている要因)と解釈できます。
また、混合行列で詳細を確認すると、0と予測したが実際は1だった、つまり予測が外れているデータ数が 34%と非常に多いことがわかります。
つまり、列の値が16 歳〜21 歳の場合、1と予測する根拠となるデータが不足していると言え、説明変数の構成を検討する材料となります。