機械が重視したデータ
モデル構築にあたり、重要な列およびその要素が把握できます。 モデル内部の把握はもちろん、要因分析の視点でも活用できる機能です。
影響度比較
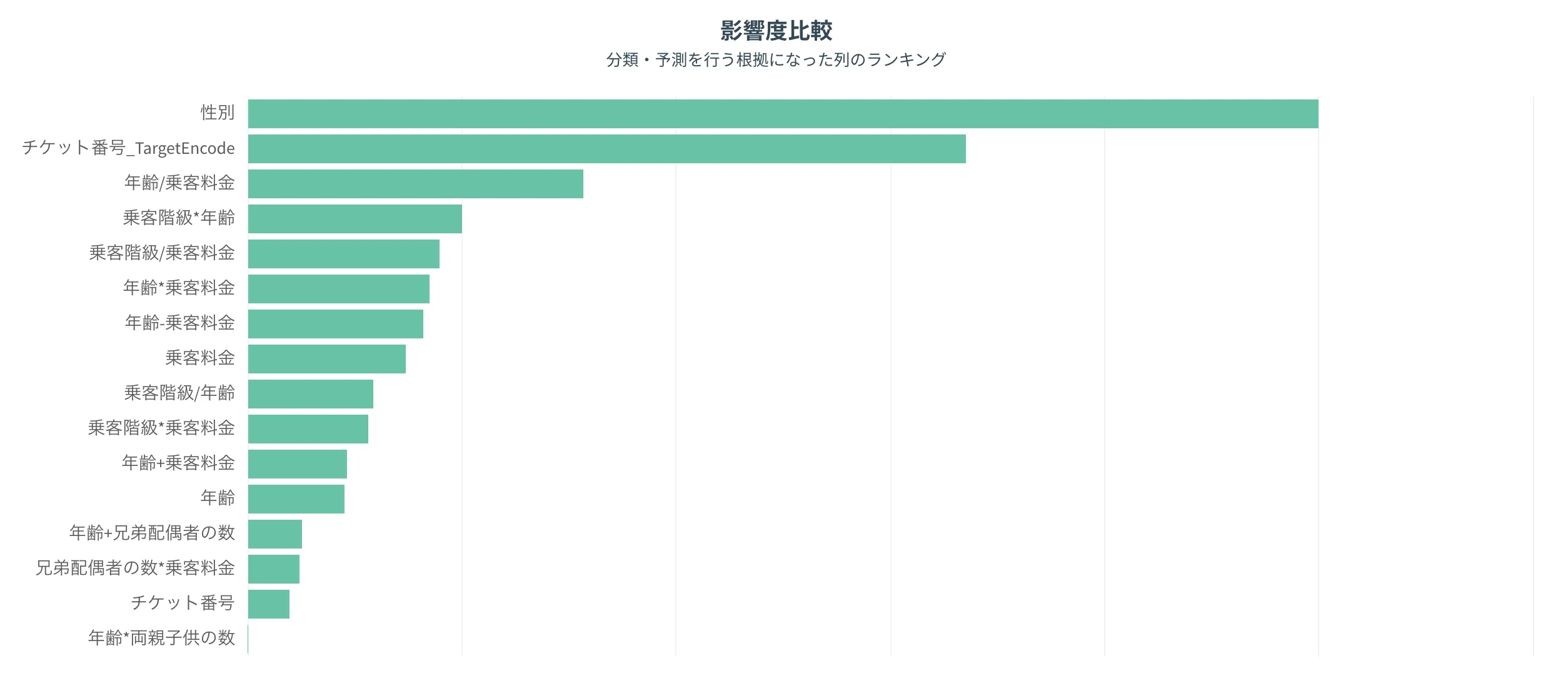
モデル構築にあたり、どの列を重視されたかが把握できます。
上にある列ほど、重要であることを意味します。
なおオート ML の場合、新規生成された列が交じる場合があります。(列 1+列 2、といった演算により生まれた新規列)
列ごとに詳細を観察
下部のフィルタボックスで列名を指定することで、その列内のどの要素が重視されたかが確認できます。
文字列の場合はカテゴリごとに、数値列の場合は数値範囲ごとに、どこに影響したかを表現します。
文字列の例
下記の性別列を題材にします。
カテゴリ分類モードでモデルを構築しています。

- 1 への分類根拠: female
- 0 への分類根拠: male
と読み取ることができ、
- 性別列の値がfemaleであれば1に
- maleであれば0に分類されやすい
と解釈できます。
数値列の例
下記の年齢列を題材にします。カテゴリ分類モードでモデルを構築しています。
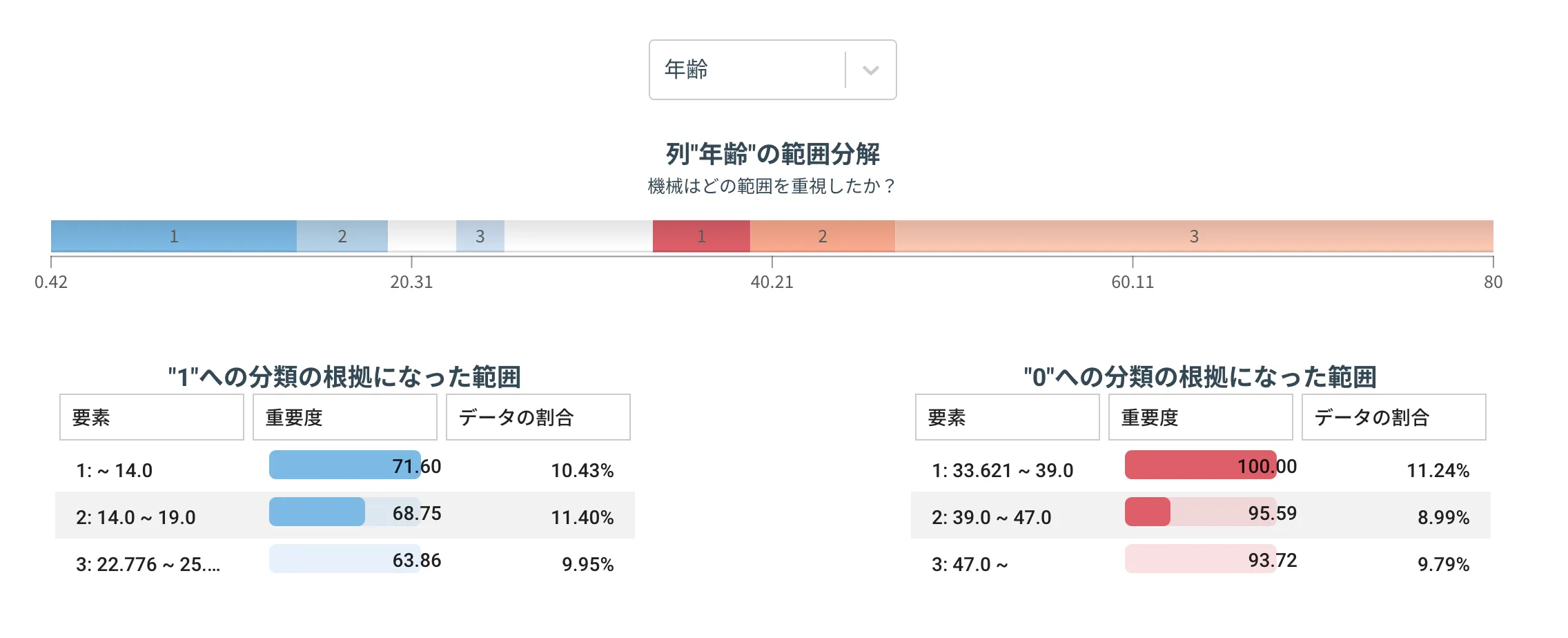
まず、範囲分解のグラフを見ると
- 年齢が低いほど青、つまり1への分類傾向が強い
- 年齢が高いほど赤、つまり0への分類傾向が強い
と読み取れます。また、数値範囲詳細に着目すると
- 14 歳以下は最も1へ分類されやすい範囲
- 33~39 際は最も0へ分類されやすい範囲
と解釈することができます。