精度検証結果
機械学習モデル構築後、まず最初に確認すべきは、構築したモデルが良い性能を期待できるか、だと考えます。
処理設定のオプション最も重視する指標で設定した指標のゲージが最も大きく表示され、その評価はトップのテキストでも表現されます。
精度指標
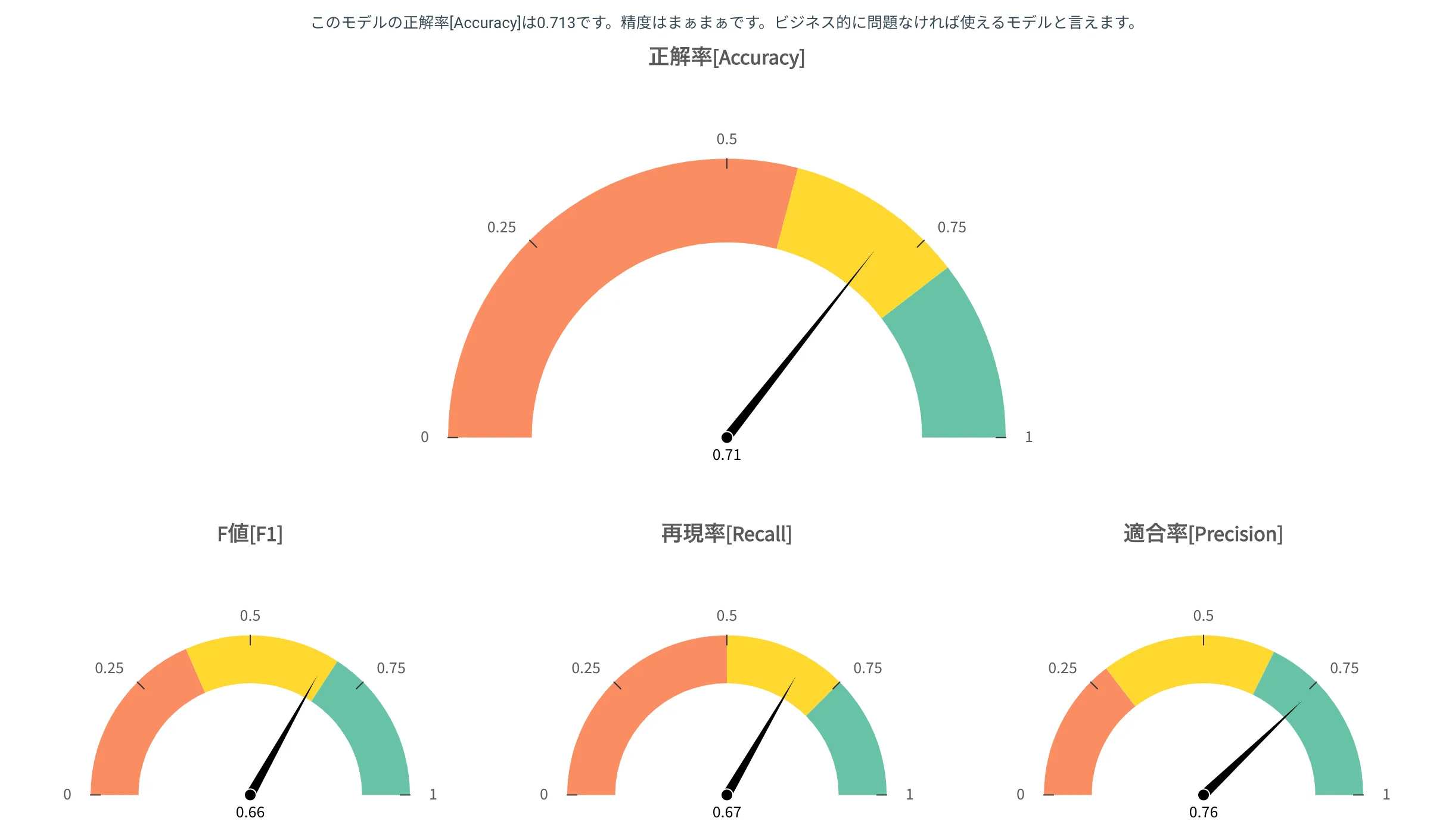
ゲージは 3 色に分かれ、針がどこを指しているかで評価を瞬時に把握できます。
- 緑: Great!
- 黄: まぁまぁ
- 赤: 低い
閾値の定義
緑、黄、赤を分ける閾値はデータによって異なります。大まかに記載すると下記の通りです。
- 赤と黄の境目: データを無視してランダムに予測した場合の予測精度
- 黄と緑の境目: MAX の精度と上記 1 との中間の値
つまり低い評価(赤)を受けたモデルは、わざわざ nehan を使って構築したのにも関わらず、適当に予測した場合より劣っているという屈辱的な評価である点に注意してください。
1 の詳細の定義については下記の通りです。
カテゴリ分類モード
予測値を全て同じカテゴリとした場合、どのくらい当たるか?を算出しています。
例えばデータの目的変数に、生存が 90 行、死亡が 10 行の場合、適当に全部生存と予測すると 90%正解になります。
ゆえに、90%を下回る精度は低い、95%以上が高いと評価されます。
数値予測モード
予測値を全て目的変数の平均値とした場合、どのくらいの誤差がでるか?を算出しています。
例えば上記の場合、平均で 10%誤差だとし、それを超えると何も考えず平均値を予測値としたほうがマシという評価になります。
ゆえに、10%誤差を上回る精度は低い、5%誤差を下回れば高いと評価されます。
カテゴリ分類の精度指標
予測結果と実際の値の混合行列を例に上げ、各指標の定義を記載します。
| 目的変数 | 1と予測 | 0と予測 |
|---|---|---|
| 実際は1 | ① | ② |
| 実際は0 | ③ | ④ |
正解率(Accuracy)
予測がどれだけ正解したか?
(① + ④) / (① + ② + ③ + ④)
再現率(Recall)
実際に正であったもののうち、どれだけ正と予測できたか?
① / (① + ②)
適合率(Precision)
正と予測したものが、どれだけ正しかったか?
① / (① + ③)
F 値(F1)
Recall と Precision を均等に評価した指標
2 * Recall * Precision / (Recall + Precision)
数値予測の精度指標
平均絶対相対誤差(MAPE)
予測が実測に対して何%くらいはずれるか?
各行ごとに|予測値 - 実測値|/実測値を算出し平均した値です。
平均絶対誤差(MAE)
予測が実測に対してどのくらいはずれるか?
各行ごとに|予測値 - 実測値|を算出し平均した値です。
二乗平均平方根誤差(RMSE)
各行ごとに(予測値-実測値)^2を算出して平均をとり、その平均値に対して平方根を取った値です。
この指標は誤差が大きい行があればあるほど、値が大きくなり、誤差を厳しく評価できる指標です。
過学習リスク

過学習とは、予測モデルがデータの細かい規則性を学習しすぎた状態のことを言います。
過学習が起きると、教師あり学習ノードで算出した精度が別のデータ(未知のデータ)で再現しない恐れがあります。
このリスクを 10 段階で評価したものを過学習リスクと呼び、大きくなればなるほど過学習している可能性が高いと言えます。
算出方法
訓練データで構築した予測モデルにて、訓練データ、検証データをそれぞれ予測し、精度の乖離度合いにてリスクを算出します。
乖離が少なければ、過学習リスクは低くなり、逆に乖離が激しいとリスクが高まります。
原因と対策
リスクが高い原因は
- 訓練データが少なすぎる
- 最適な機械学習パラメータなどを探索しすぎている
等が挙げられます。
これらは処理モードのカスタム設定にてコントロールができ、調整することでリスクが下がる可能性があります。
混合行列
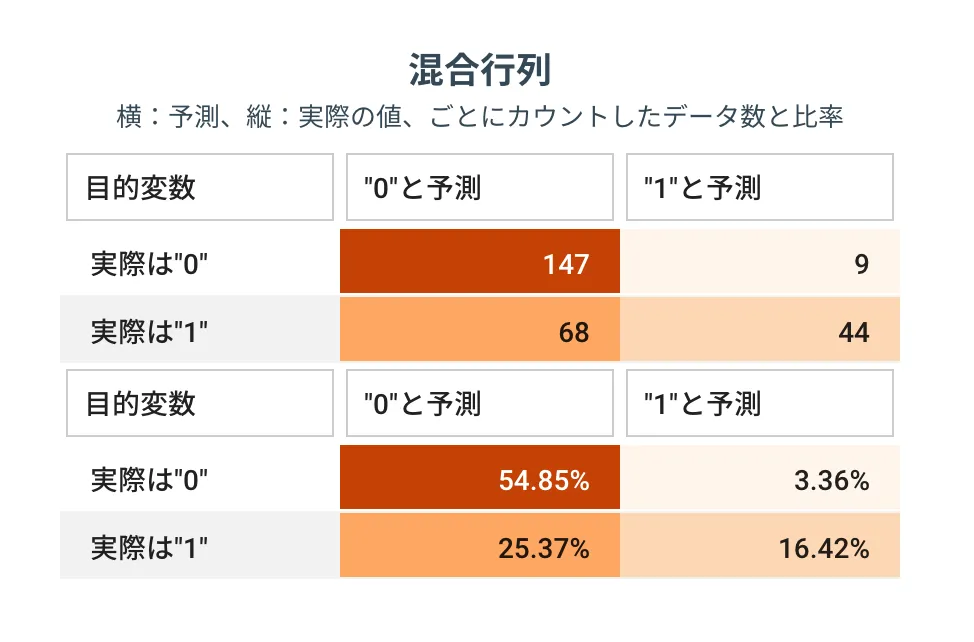
予測の正解状況をより細かく観察できます。
予測を外したケースだと例えば、xと予測したけど(横)実際はy(縦)のデータの個数 or 何%あるか、が確認できます。
どこで予測が外れているのか、を認識することで、精度改善のヒントを得られる可能性があります。
数値予測の場合
目的変数(実測値)の最小値から最大値までの範囲をデータの数が等しくなるように 5 等分し、各範囲ごとに予測と実測のデータ数を比較できるようにしています。
精度分解
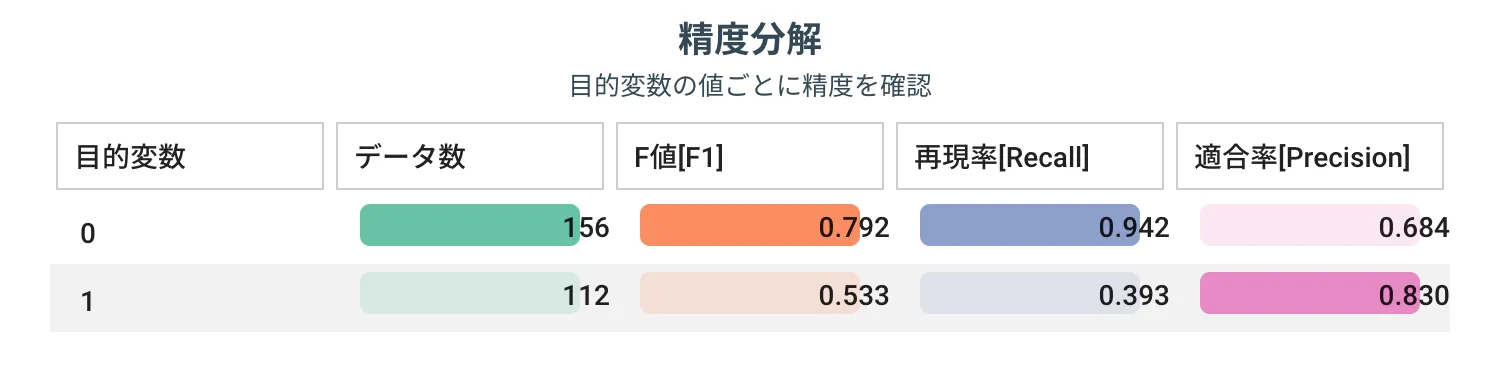
分類であればカテゴリごと、数値予測であれば範囲ごとに、指標を比較できます。
例えば生存と死亡の 2 値分類を予測する場合、生存と予測できないのか?それとも死亡と予測できていないのか?を把握することが可能です。
学習曲線
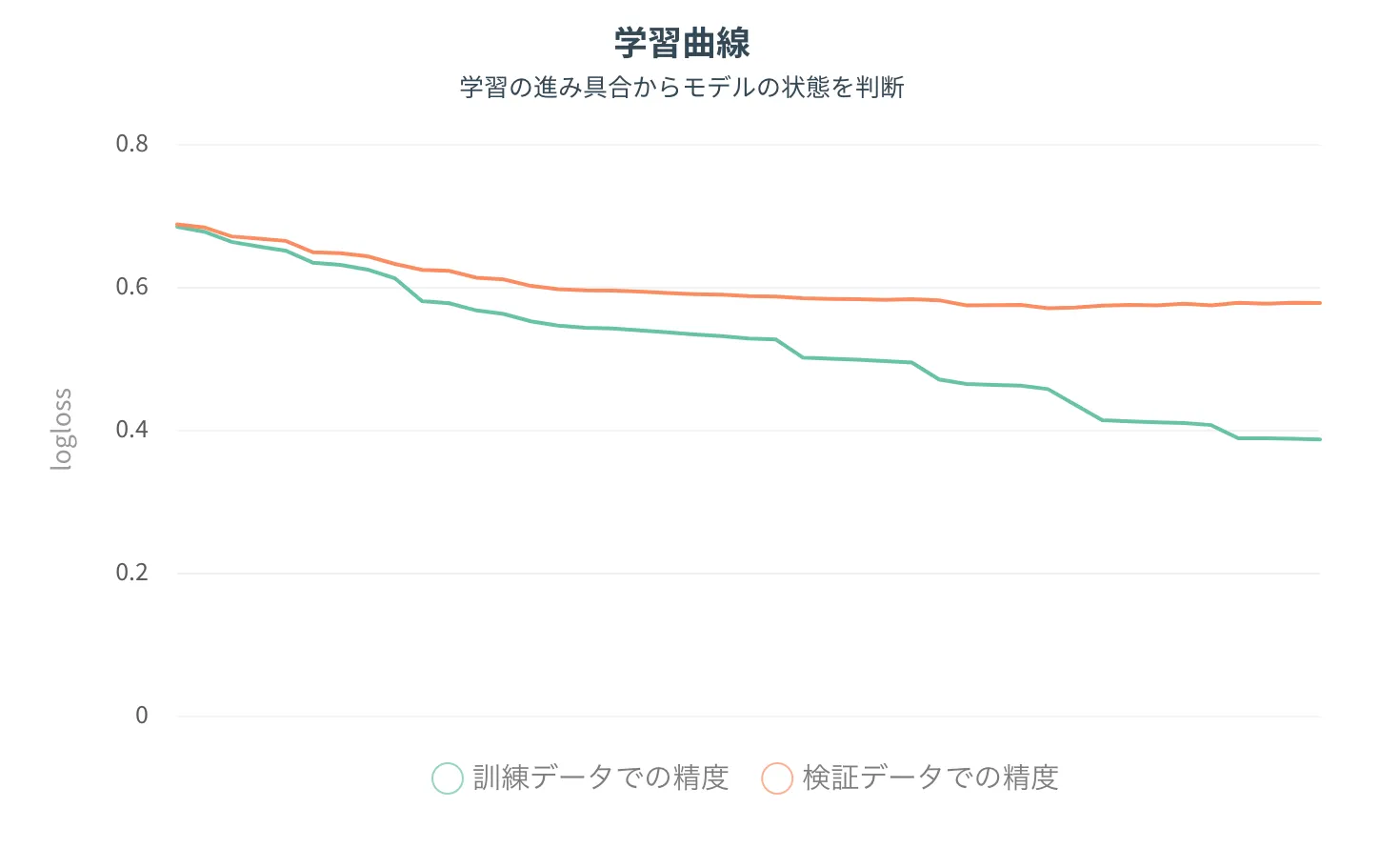
ブースティングタイプの学習アルゴリズムXGBoost、LightGBMのみ表示される補助情報です。
上記の過学習リスクと近しい情報を得ることができ訓練データの精度と検証データの精度が右に行くとどれだけ乖離するかが注目点です。
乖離が激しいと過学習のリスクが高いと言えます。